Мониторинг в Cloud Console ClickHouse
Сервисы в ClickHouse Cloud включают готовые компоненты мониторинга с панелями мониторинга и уведомлениями. По умолчанию доступ к этим панелям мониторинга есть у всех пользователей в Cloud Console.
Панели мониторинга
Состояние сервиса
Панель мониторинга состояния сервиса можно использовать, чтобы мониторить общее состояние сервиса. ClickHouse Cloud собирает и хранит метрики для этой панели мониторинга из системных таблиц, чтобы их можно было просматривать, когда сервис бездействует.
Использование ресурсов
Панель мониторинга Infrastructure предоставляет подробную информацию о ресурсах, используемых процессом ClickHouse. ClickHouse Cloud собирает и хранит метрики, отображаемые на этой панели мониторинга, из системных таблиц, чтобы их можно было просматривать, когда сервис бездействует.
Память и CPU
Графики Выделенный CPU и Выделенная память показывают общий объем вычислительных ресурсов, доступных для каждой реплики в вашем сервисе. Эти значения можно изменить с помощью масштабирования в ClickHouse Cloud.
Графики Использование памяти и Использование CPU показывают оценку того, сколько CPU и памяти фактически используется процессами ClickHouse в каждой реплике, включая запросы и фоновые процессы, такие как слияния.
Если использование памяти или CPU приближается к выделенному объему памяти или CPU, вы можете столкнуться со снижением производительности. Чтобы это исправить, рекомендуем:
- Оптимизировать запросы
- Изменить партиционирование таблиц
- Добавить сервису больше вычислительных ресурсов с помощью масштабирования
Ниже приведены соответствующие метрики из системных таблиц, отображаемые на этих графиках:
| График | Имя соответствующей метрики | Агрегация | Примечания |
|---|---|---|---|
| Выделенная память | CGroupMemoryTotal | Max | |
| Выделенный CPU | CGroupMaxCPU | Max | |
| Используемая память | MemoryResident | Max | |
| Используемый CPU | Системная метрика CPU | Max | ClickHouseServer_UsageCores через конечную точку Prometheus |
Передача данных
Графики отображают входящий и исходящий трафик данных в ClickHouse Cloud и из него. Подробнее см. в разделе передача данных по сети.
Расширенная панель мониторинга
Эта панель мониторинга представляет собой измененную версию встроенной расширенной панели мониторинга обсервабилити, в которой каждый ряд показывает метрики для отдельной реплики. Эта панель мониторинга может быть полезна для мониторинга и устранения неполадок, специфичных для ClickHouse.
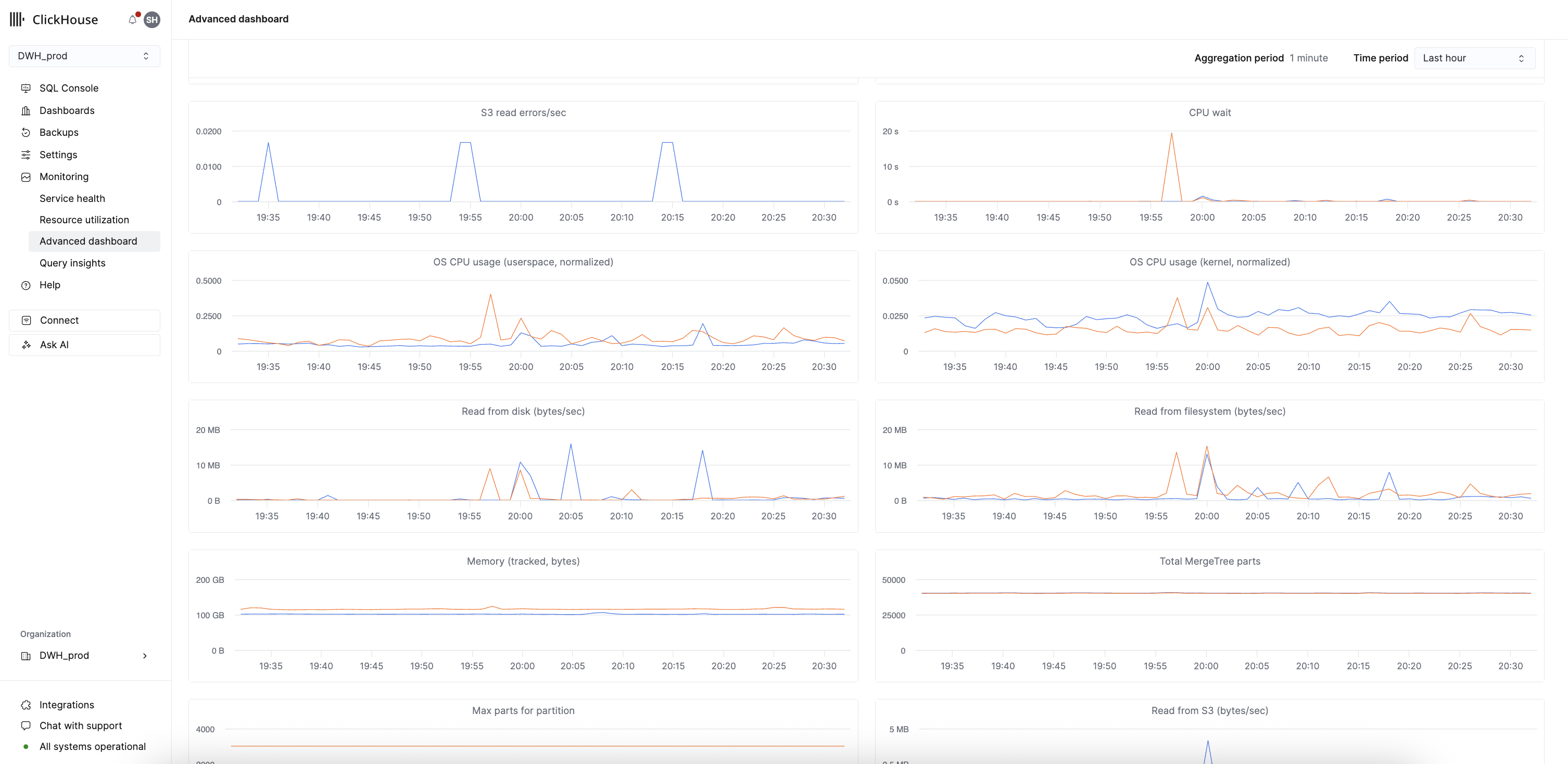
ClickHouse Cloud собирает и хранит метрики, отображаемые на этой панели мониторинга, из системных таблиц, чтобы их можно было просматривать, даже когда сервис находится в бездействующем состоянии. Доступ к этим метрикам не отправляет запрос к базовому сервису и не выводит бездействующие сервисы из состояния idle.
В таблице ниже каждому графику на расширенной панели мониторинга сопоставлены соответствующая метрика ClickHouse, исходная системная таблица и тип агрегации:
| График | Имя соответствующей метрики ClickHouse | Системная таблица | Тип агрегации |
|---|---|---|---|
| Запросы/сек | ProfileEvent_Query | metric_log | Sum / bucketSizeSeconds |
| Выполняющиеся запросы | CurrentMetric_Query | metric_log | Avg |
| Выполняющиеся слияния | CurrentMetric_Merge | metric_log | Avg |
| Выбранные байты/сек | ProfileEvent_SelectedBytes | metric_log | Sum / bucketSizeSeconds |
| Ожидание IO | ProfileEvent_OSIOWaitMicroseconds | metric_log | Sum / bucketSizeSeconds |
| Ожидание чтения из S3 | ProfileEvent_ReadBufferFromS3Microseconds | metric_log | Sum / bucketSizeSeconds |
| Ошибки чтения из S3/сек | ProfileEvent_ReadBufferFromS3RequestsErrors | metric_log | Sum / bucketSizeSeconds |
| Ожидание CPU | ProfileEvent_OSCPUWaitMicroseconds | metric_log | Sum / bucketSizeSeconds |
| Использование CPU ОС (пользовательское пространство, нормализованное) | OSUserTimeNormalized | asynchronous_metric_log | |
| Использование CPU ОС (ядро, нормализованное) | OSSystemTimeNormalized | asynchronous_metric_log | |
| Чтение с диска | ProfileEvent_OSReadBytes | metric_log | Sum / bucketSizeSeconds |
| Чтение из файловой системы | ProfileEvent_OSReadChars | metric_log | Sum / bucketSizeSeconds |
| Память (отслеживаемая, байты) | CurrentMetric_MemoryTracking | metric_log | |
| Общее количество частей MergeTree | TotalPartsOfMergeTreeTables | asynchronous_metric_log | |
| Макс. количество частей для партиции | MaxPartCountForPartition | asynchronous_metric_log | |
| Чтение из S3 | ProfileEvent_ReadBufferFromS3Bytes | metric_log | Sum / bucketSizeSeconds |
| Размер файлового кэша | CurrentMetric_FilesystemCacheSize | metric_log | |
| Запросы записи на диск S3/сек | ProfileEvent_DiskS3PutObject + ProfileEvent_DiskS3UploadPart + ProfileEvent_DiskS3CreateMultipartUpload + ProfileEvent_DiskS3CompleteMultipartUpload | metric_log | Sum / bucketSizeSeconds |
| Запросы чтения с диска S3/сек | ProfileEvent_DiskS3GetObject + ProfileEvent_DiskS3HeadObject + ProfileEvent_DiskS3ListObjects | metric_log | Sum / bucketSizeSeconds |
| Доля попаданий в кэш FS | sum(ProfileEvent_CachedReadBufferReadFromCacheBytes) / (sum(ProfileEvent_CachedReadBufferReadFromCacheBytes) + sum(ProfileEvent_CachedReadBufferReadFromSourceBytes)) | metric_log | |
| Доля попаданий в кэш страниц | greatest(0, (sum(ProfileEvent_OSReadChars) - sum(ProfileEvent_OSReadBytes)) / (sum(ProfileEvent_OSReadChars) + sum(ProfileEvent_ReadBufferFromS3Bytes))) | metric_log | |
| Полученные по сети байты/сек | NetworkReceiveBytes | asynchronous_metric_log | Sum / bucketSizeSeconds |
| Отправленные по сети байты/сек | NetworkSendBytes | asynchronous_metric_log | Sum / bucketSizeSeconds |
| Одновременные TCP-подключения | CurrentMetric_TCPConnection | metric_log | |
| Одновременные MySQL-подключения | CurrentMetric_MySQLConnection | metric_log | |
| Одновременные HTTP-соединения | CurrentMetric_HTTPConnection | metric_log |
Подробную информацию о каждой визуализации и о том, как использовать их для устранения неполадок, см. в документации по расширенной панели мониторинга.
Query insights
Функция Query Insights упрощает работу со встроенным журналом запросов ClickHouse благодаря различным визуализациям и таблицам. Таблица ClickHouse system.query_log — ключевой источник информации для оптимизации запросов, отладки, мониторинга общего состояния кластера и его производительности.
После выбора сервиса пункт Monitoring на левой боковой панели навигации раскрывается и показывает подпункт Query insights:
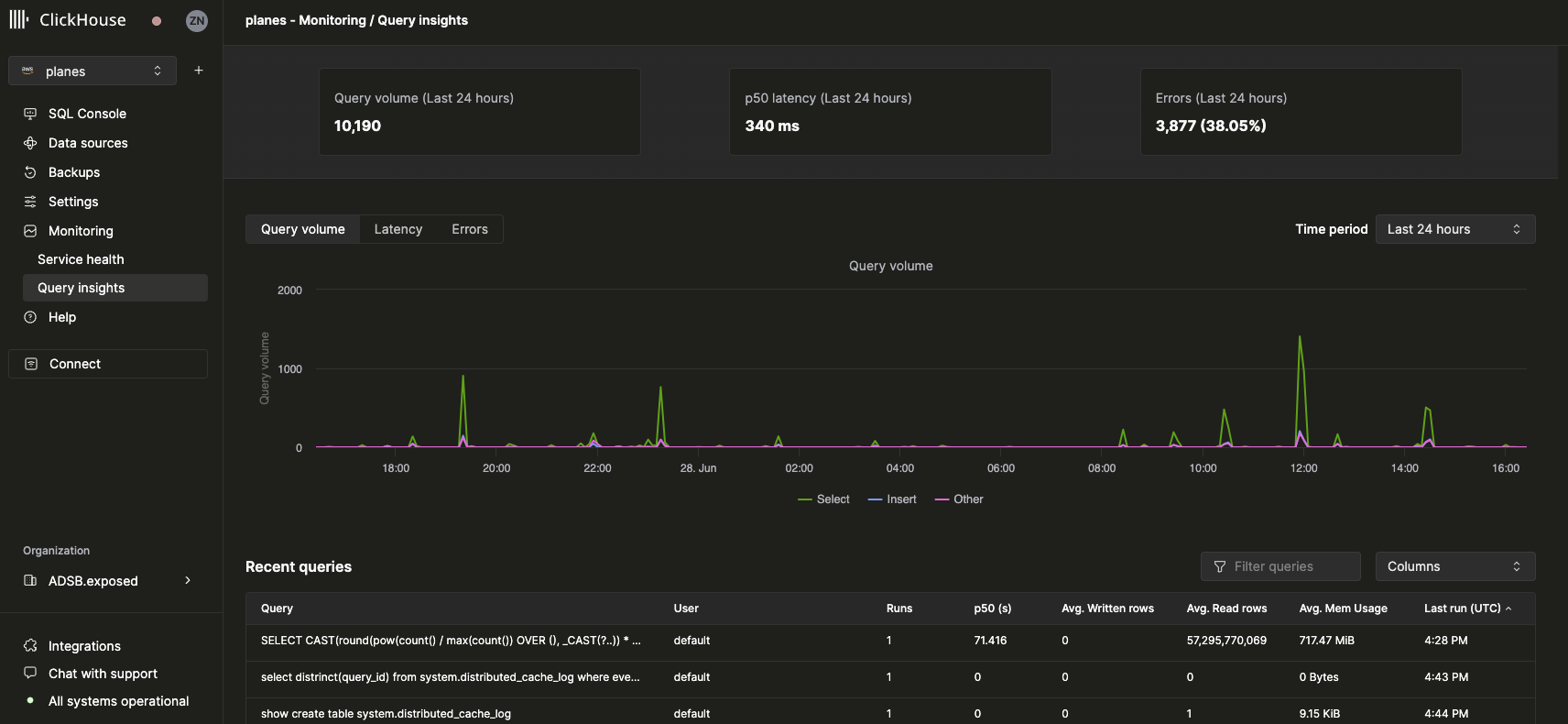
Основные метрики
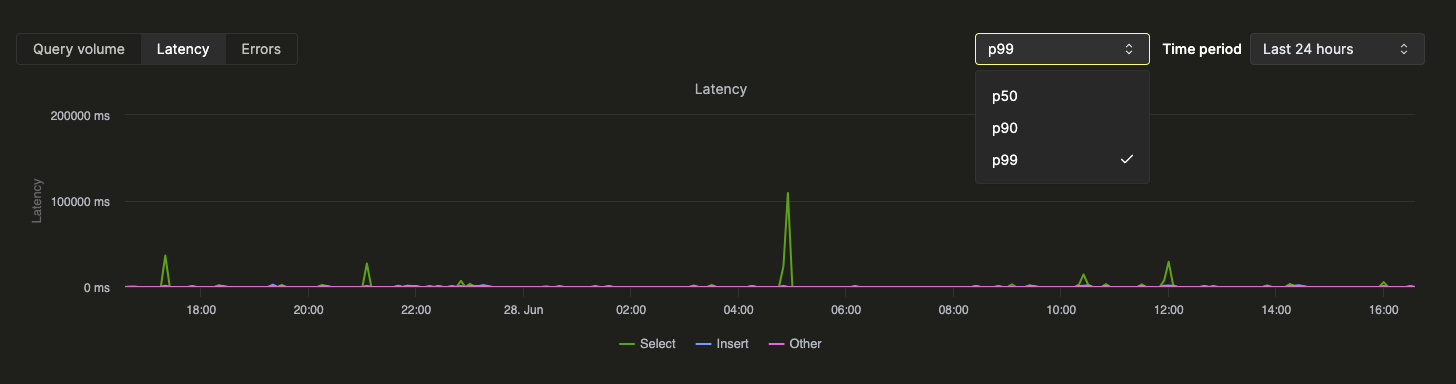
Статистические карточки вверху показывают базовые метрики запросов за выбранный период времени. Под ними графики временных рядов отображают объём запросов, задержку и частоту ошибок с разбивкой по виду запроса (select, insert, other). График задержки можно настроить для отображения задержек p50, p90 и p99:
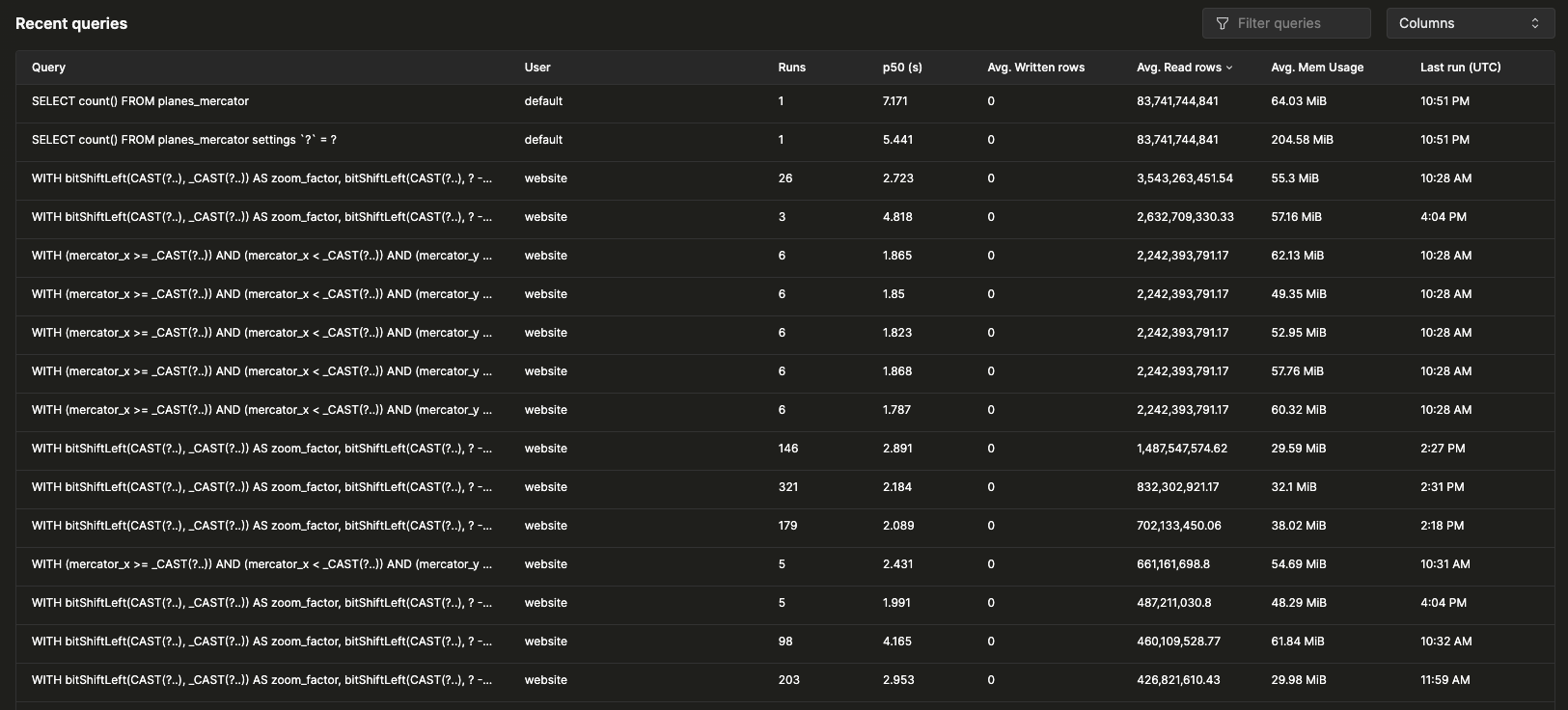
Последние запросы
В таблице отображаются записи лога запросов, сгруппированные по нормализованному хешу запроса и пользователю в пределах выбранного временного окна. Последние запросы можно фильтровать и сортировать по любому доступному полю, а таблицу можно настроить так, чтобы отображать или скрывать дополнительные поля, такие как таблицы, задержки p90 и p99:
Детализация запроса
При выборе запроса из таблицы последних запросов откроется выезжающая панель с метриками и информацией по выбранному запросу:
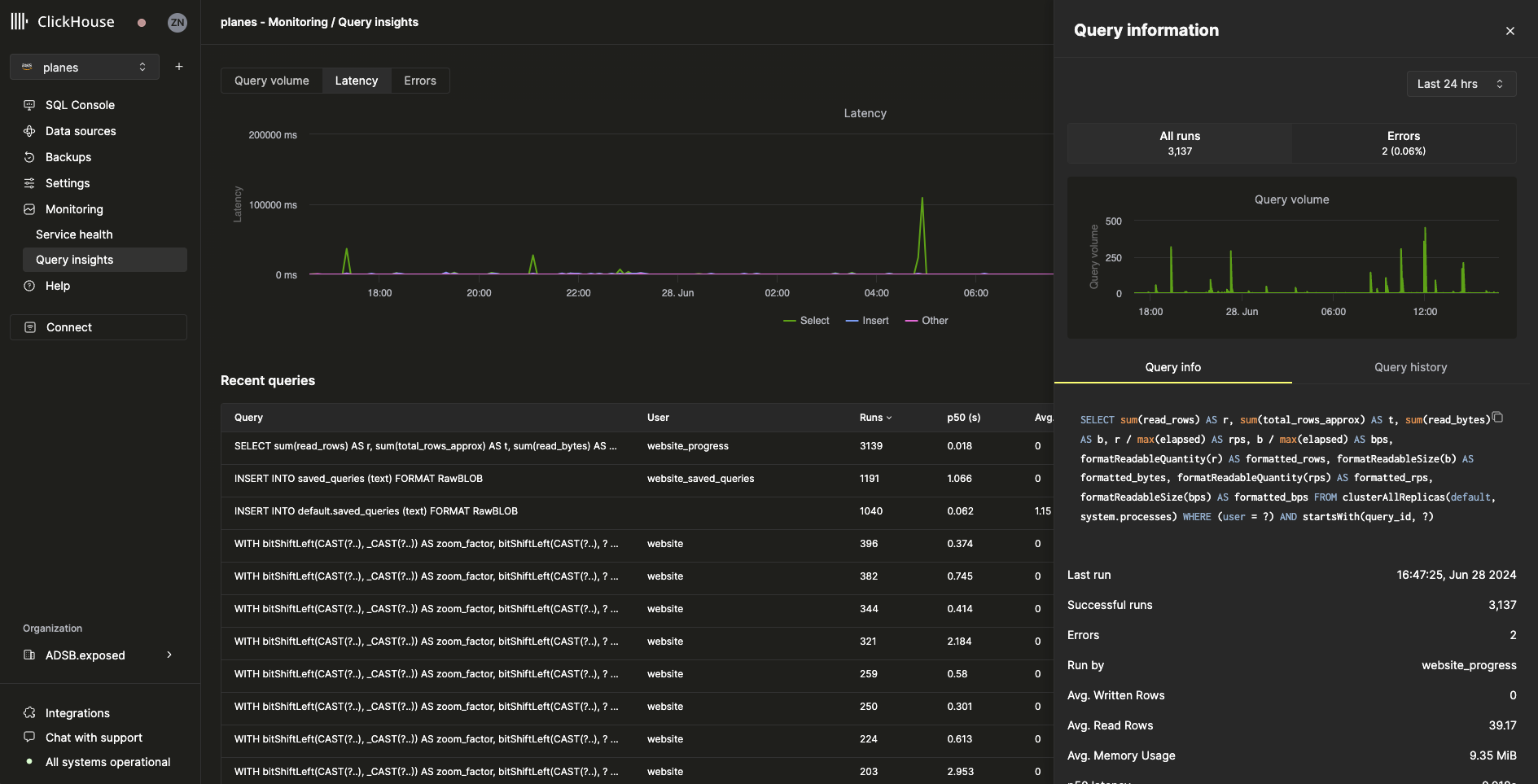
Все метрики на вкладке Query info являются агрегированными, однако метрики отдельных запусков также можно просматривать на вкладке Query history:
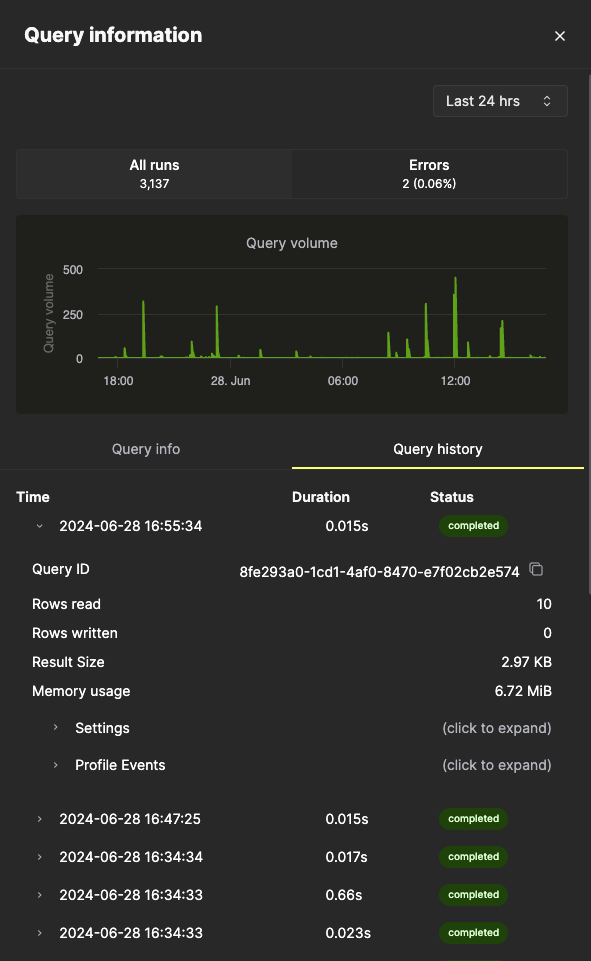
В этой панели можно развернуть элементы Settings и Profile Events для каждого запуска запроса, чтобы увидеть дополнительную информацию.
Связанные страницы
- Уведомления — Настройте оповещения о событиях масштабирования, ошибках и биллинге
- Расширенная панель мониторинга — Подробное справочное описание каждой визуализации на панели мониторинга
- Запросы к системным таблицам — Выполняйте пользовательские SQL-запросы к системным таблицам для детального анализа
- Prometheus endpoint — Экспортируйте метрики в Grafana, Datadog и другие инструменты, совместимые с Prometheus
